
The Great Decoupling: Separating Your SIEM from Your Data Layer
Why security teams are rethinking data ownership in the SOC

Welcome to The Cybersecurity Pulse (TCP)! I’m Darwin Salazar, Head of Growth at Monad and former detection engineer in big tech. Each week, I bring you the latest security innovation and industry news. Subscribe to receive weekly updates! 📧

The core architecture of SIEMs was never designed to solve modern SOC problems. Think ingesting 5TB/day of logs from 40+ sources, varying schemas, log quality, and low fidelity atomic alerts. It’s why forward-thinking teams at HSBC, Rippling, Brex and countless others are decoupling their data pipeline from their SIEM. AI/ML tooling has put a magnifying glass to this problem. Models don’t tolerate messy or incomplete data the way humans do.
After years as a security consultant and detection engineer, I've concluded that the data layer must be decoupled from the SIEM. The science nor the math make sense anymore and it hasn't for a while.
That conviction is why I've spent the past 2.5 years working on this problem at Monad, so I'm not unbiased. The timing has always felt right, but now it feels more important than ever. In this post, I'll highlight why.
Built to Search, Paid to Ingest
SIEMs were designed to be search engines with alerting capabilities. Somewhere along the way, vendors realized they could charge per gigabyte ingested, and log ingestion became a revenue driver rather than a customer success priority.
Think about what the SIEM actually does well: indexing logs, running queries, correlating events, creating historical baselines, and firing alerts.
Now think about what most SIEMs claim to do: collect data from N sources, normalize it into a consistent schema, route it to themselves, transform it and enrich it.
These are fundamentally different disciplines. The architectures don’t overlap. And the incentive structures definitely don’t overlap. SIEM vendors maintain hundreds of integrations across thousands of customers while adding AI SOC, SOAR, UEBA, agentic threat hunting, risk scoring and countless other features. They’re generalist platforms that thrive in search and alerting, not data engineering.
SIEM vendors make money when you ingest more data. They have zero incentive to help you route logs to cold storage at a fraction of the cost or send copies to your data lake for ML experiments.

Lock-in doesn’t hurt on day one. It hurts on year three when your vendor raises prices 40% and you realize your entire detection library, your normalized schemas, your enrichment logic, and your historical data are all trapped in a proprietary format and it would take 6+ months to migrate.
The Multi-Destination Era
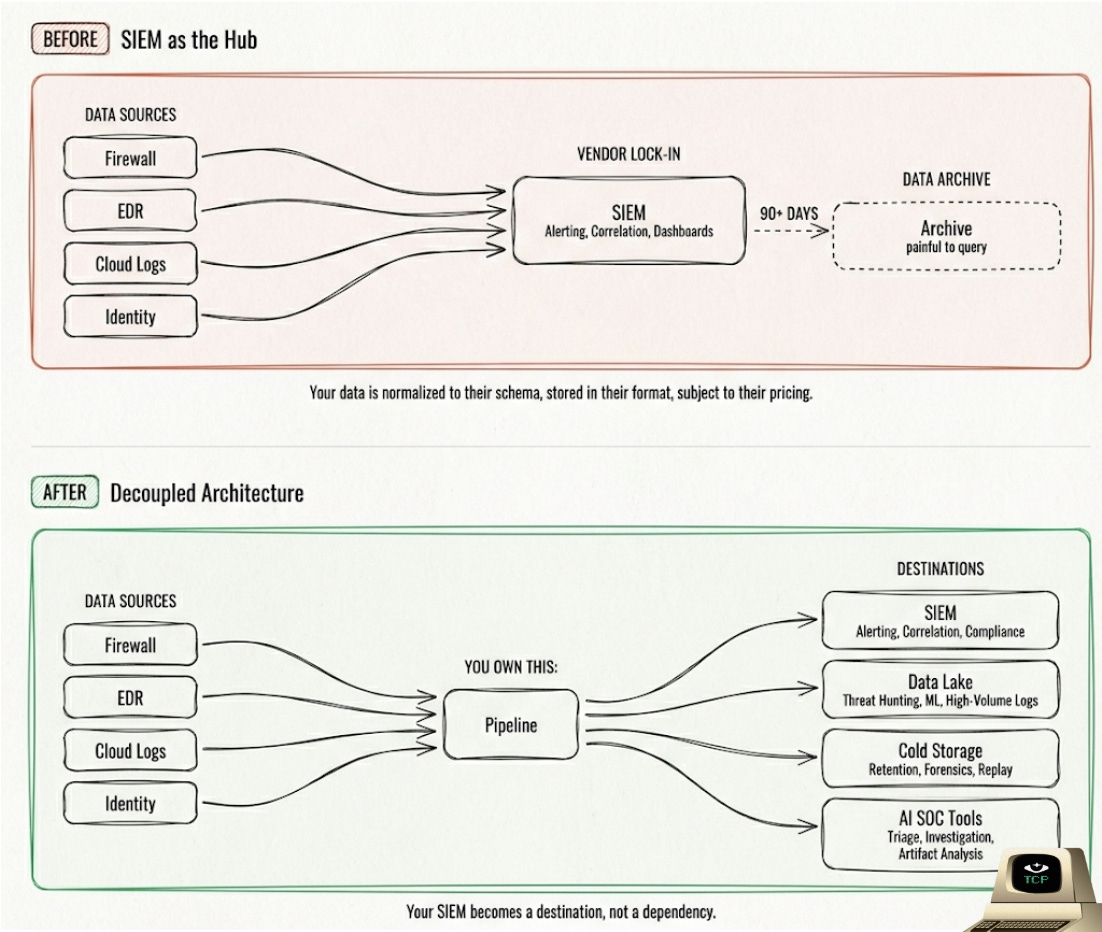
Security data needs to live in more places than ever:
SIEM for real-time detection and response
Data lake + BI for threat hunting, dashboarding, and homegrown AI/ML
Cold storage for compliance and incident response replay
AI triage tools and analytics platforms that need access to the same telemetry
Now try to accomplish this with your SIEM as the central hub. Most SIEMs have little to no native support for routing data to external destinations.
Splunk, for example, has no native integration to send data to Databricks or ClickHouse. This is the routing compatibility problem, and it’s only gotten worse as security teams adopt more specialized tools and the enterprise sprawls into more SaaS and AI apps.
Interested in Sponsoring TCP?
TCP partners with a handful of sponsors each quarter. If your company is building something practitioners should know about, let’s chat.
AI Doesn't Fix Bad Data
AI is changing how security teams operate, and every AI use case lives or dies on data quality and availability.
AI-powered SOC triage is the future. But right now, these tools are not ready for full unsupervised production use. Data availability and quality are the main culprits.
Talk to folks who have POC’d AI SOC vendors and you’ll hear they demo beautifully, reduce MTTR tremendously, and the UI is neat. But when digging into the actual triage output and reasoning, you may find the AI described a full attack chain: cmd.exe spawned PowerShell, which spawned certutil. But the actual data only had the certutil execution. The parent process fields were null. That's a model failure and a data failure. But only one of them is fixable upstream (unless you own + fine-tune your model).
When AI triage agents ingest unnormalized logs, heavily nested JSON with inconsistent field names, or events missing critical context, they hallucinate. They correlate events that shouldn’t be correlated because timestamps are formatted differently across sources. They miss obvious conclusions because the enrichment data that would make it obvious was never joined.
AI SOCs are only as good as the data they can access:
No HR data? Can’t understand org structure.
No asset inventory? Can’t distinguish a server from a laptop.
Missing identity logs? Flying blind on user behavior.
When your SIEM owns the pipeline, your data is normalized to their schema, optimized for their query engine, stored in their proprietary format. The organizations that stand to gain the most from AI in security have full control over their data layer.
Credit where it’s due: Some AI SOC vendors like Prophet Security and Intezer aren’t just throwing LLMs at messy data and hoping for the best. They’re taking more deterministic, evidence-based approaches that surface data gaps rather than hallucinating over them.
What Decoupling Actually Looks Like
Decoupling means separating concerns, not building everything yourself.
Your data pipeline handles collection, parsing, normalization, enrichment, and routing. Source-agnostic. Destination-agnostic. Your SIEM / data lake receives clean, enriched data and does what it was built for: detection and investigation.
Purpose-built pipelines offer better filtering, routing flexibility, scalability, and observability. Typically at a fraction of SIEM ingestion costs.
This also gives you optionality:
Migrate SIEMs? Your pipeline stays intact.
Add a data lake? Add a route.
Experiment with AI-powered triage? Run platforms in parallel without doubling ingestion costs.
Vendor plays pricing games? You have real leverage to walk away.
When you own your pipeline, your SIEM becomes a destination, not a dependency.
The Path Forward
The window is open. SIEMs were never designed to be data pipelines, and the architecture+incentive mismatch is more obvious than ever. Vendor lock-in is getting harder to justify when budgets are tight and better options exist. AI capabilities are finally practical but demand clean data to function. The teams that own their pipeline will be the ones who actually get value from what comes next.
This is the problem we’re solving at Monad. We’re building a security data pipeline platform that gives teams full control over collection, normalization, enrichment, and routing. No vendor lock-in. No ingestion taxes. Just clean data flowing where it needs to go.
If you’re dealing with SIEM cost overruns, data quality issues, or want to future-proof your stack for AI, let’s talk.
Disclaimer
The insights, opinions, and analyses shared in The Cybersecurity Pulse are my own and do not represent the views or positions of my employer or any affiliated organizations. This newsletter is for informational purposes only and should not be construed as financial, legal, security, or investment advice.
‘Vendor lock-in is getting harder to justify when budgets are tight and better options exist. AI capabilities are finally practical but demand clean data to function. The teams that own their pipeline will be the ones who actually get value from what comes next’
well said imo. this was a great read thanks 😊
I thought the "ai doesn't fix bad data" portion was spot on. The scale and speed required for enterprise scale like you mentioned is really hard. Imagine having a complete forensic toolset for triage that actually captures the full attack path every time, that judiciously gives verdicts at scale, and accurately. Proving that capability out would take really large enterprises to validate it, but once they did, I'd think the whole operating model then changes for triage/investigation/verdict. AND it plays directly into exactly what Monad provides on the pipeline side, what a 1-2 punch combo!